Паевой инвестиционный фонд (ПИФ) - это компания, которая объединяет деньги многих инвесторов и инвестирует их в ценные бумаги: акции, облигации, краткосрочные долговые облигации. Объединенные активы ПИФ назывется портфелем. Инвесторы покупают акции паевых инвестиционных фондов
Паевые инвестиционные фонды являются одним из наиболее простых и прибыльных инструментов инвестирования. Главная цель таких фондов – объединить капитал многих участников и эффективно инвестировать. Их называют фондами коллективного инвестирования.
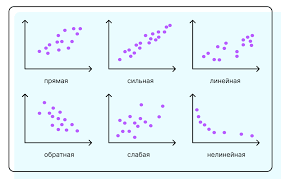
Корреляция (от лат. correlatio «соотношение») — это взаимосвязь между разными показателями в статистике. Например, когда один показатель увеличивается, другой уменьшается — или тоже увеличивается. Корреляцию используют, чтобы оценить зависимость переменных друг от друга.
Если два показателя коррелируют друг с другом, выше вероятность, что они как-то связаны: например, один зависит от другого или они оба зависят от третьей переменной.
Корреляция может быть:
С помощью корреляции определяют, как одна переменная меняется относительно другой — это определение из статистики. Это нужно, чтобы оценить, насколько показатели могут быть взаимосвязаны.
Корреляция — это не зависимость. Если две переменные коррелируют друг с другом — это еще не значит, что между ними есть причинно-следственная связь. Причины корреляции нужно исследовать отдельно — чтобы понять, как именно могут быть связаны показатели.
Корреляция может быть случайной. Иногда друг с другом коррелируют показатели, которые вообще не связаны и никак не зависят один от другого. Есть целый сайт, где собраны абсурдные корреляции: например, чем меньше люди потребляют маргарина, тем меньше разводов в штате Мэн. Корреляция — больше 99%! Понятно, что связи тут, скорее всего, нет, просто совпадение. Такое явление называют spurious correlation, или ложной корреляцией.
Несмотря на риск простого совпадения, чаще всего корреляция все же помогает найти неочевидные связи между переменными. Связи могут быть различными:
Вот пример: продажи мороженого коррелируют с количеством лесных пожаров. Да, эти факторы не связаны напрямую, но есть третья переменная, которая влияет на оба: жаркая погода.
Вывод не всегда такой очевидный, как в примере выше. Поэтому корреляцию не стоит использовать как окончательный результат исследования, но не нужно и недооценивать возможную связь.
Корреляция может быть оценена различными методами, включая линейную корреляцию, которая предполагает существование линейной зависимости между переменными, а также непараметрическую корреляцию, которая не требует предположения о форме распределения данных. Для интерпретации корреляции важно учитывать контекст и особенности данных. Например, в анализе данных в науке и бизнесе корреляция может использоваться для прогнозирования и принятия решений.
Дисперсия в статистике — это мера, которая показывает разброс между результатами. Если все они близки к среднему, дисперсия низкая. А если результаты сильно различаются — высокая.
Если говорить о всей выборке, дисперсия показывает, насколько разнородны результаты. Например, в одной группе почти все — шатены. В другой половина — шатены, а остальные — блондины, рыжие и брюнеты. Вторая группа более разнородная, в ней выше дисперсия.
Более близкие к реальному миру примеры:
Еще дисперсия показывает вероятность того, что конкретный результат будет далек от среднего. Например, средний рост россиянина мужского пола — 175 см. Но если остановить на улице случайного мужчину, вряд ли он окажется ровно 175 см ростом — скорее всего, выше или ниже. Дисперсия высокая — вероятность встретить «не среднее» значение выше.
В реальном мире это можно использовать так:
Логика тут такая: чем меньше предсказуемости — тем больше хаоса и, соответственно, больше рисков.
Сначала дадим формальное определение, а потом объясним простыми словами. Дисперсия рассчитывается по формуле как среднее квадратичное отклонение от среднего значения:
D(X) =1ni=1n(xi-x)2 ,
где
n — количество элементов,
xi – i-й элемент в выборке,
x — среднее арифметическое.
Звучит и выглядит сложно, но фактически все не так страшно. Вот как выглядит расчет пошагово:
Формула дисперсии случайной величины рассчитывается так: D(X)=M(X?M(X))2
Найти дисперсию случайной величины также можно по формуле, записанной в более удобном для расчетов виде: D(X)=M(X2)?(M(X))2.
Все перечисленное посчитать несложно — достаточно школьных знаний математики. А вот чтобы понять, почему формула именно такая, уже нужно разбираться в статистике.